
Die neueste Entwicklung im Datenmanagement der IT befasst sich mit dem Data Mesh und mit Data as a Product. Die Strategie verspricht Anpassungsfähigkeit, Skalierbarkeit, Schnelligkeit und Agilität. Das ist genau das, was Self-Services in Datenanwendungen benötigen. Und es verspricht den Anwendern die Autonomie und Flexibilität, die nur mit einer dezentralen Lösung möglich sind. Im Controlling und bei der Steuerung von Unternehmen sind dies wichtige Anforderungen. Grund genug, dass wir uns das näher ansehen.
Data Mesh und Data as a Product
Mit der Idee von Data Mesh und Data as a Product liegt eine ernsthafte Strategie für eine dezentrale Verwaltung von Daten und das Design von Anwendungen vor. Das Data Mesh gibt einer Bewegung einen Namen, die es dem Self-Service Ansatz erlaubt Daten effektiver zu nutzen. Data Mesh beinhaltet die Idee der organisatorischen Dezentralisierung, die durch die Idee des Domänen-spezifischen Eigentums an Daten und Datenprodukten, der Self-Service-Datenplattform und der computergestützten Governance unterstrichen wird.
Data as a Product ist dabei ein Schlüsselkonzept, weil der Idee ein organisatorisches Paradigma zugrunde liegt.
- Ein Datenprodukt ist ein spezifisches Datenobjekt, das für verschiedene Zwecke verwendet werden kann. Es ist so gestaltet, dass es verlässliche Informationen für seine Nutzer gewährleistet, die dabei als Kunden betrachtet werden. Die Idee verstärkt so die Vorstellung von Produkten, die immer einen klaren kundenorientierten Zweck haben.
- Und Datenprodukte unterscheiden sich auch von Datenprojekten, weil Projekte immer ein geplantes Ende haben. Mit dem Datenprodukte wird ein Umfeld geschaffen, in dem sich die Dinge ändern und weiterentwickeln können. Eigenschaften eines Produktes wie Verantwortlichkeit, Modularität, Marketing usw. sind entscheidend und vorteilhaft, wenn es darum geht das Datenprodukt an Veränderungen anzupassen, ohne an Qualität zu verlieren.
Als Konzept für das Management von Daten in der IT ist dies ein großartiger Ansatz, der sicherlich in der Lage ist Flexibilität und Qualität miteinander in Einklang zu bringen.
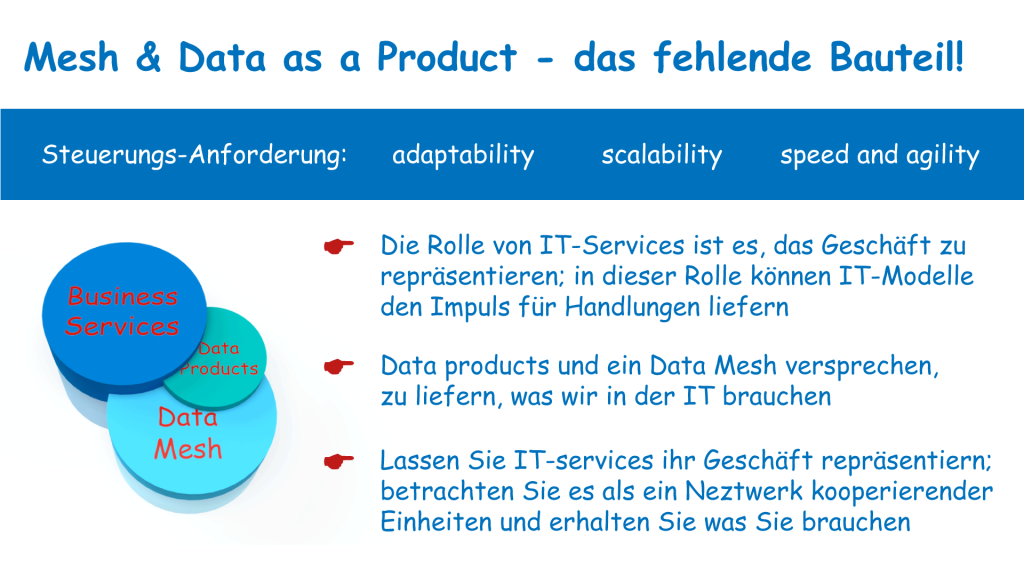
Für den erfolgreichen Einsatz im Geschäft fehlt ein Stück
Wenn wir das Konzept des Data Mesh und von Data as a Product nutzen wollen, dann müssen wir uns aber auch darum kümmern, welche Datenprodukte wir identifizieren können und verwenden wollen. Die Datenverarbeitung ist in einem Unternehmen nämlich genau deshalb wirksam, weil IT-Services Geschäftsfunktionen repräsentieren können und sich dann aus den in der IT verwendeten Modellen Impulse für konkretes Handeln ableiten lassen. Wir müssen also wissen, was repräsentiert werden soll.
Bei dieser Aufgabe hilft uns die Idee der Modularisierung von geschäftlichen Leistungen. Aus der Theorie der sozialen Systeme wissen wir, dass komplizierte Aufgaben in Module zerlegt werden können. Sie spezialisieren sich dabei auf Teile der Aufgabe und folgen den Verhaltensregeln von sozialen Systemen. Die Module handeln als Agenten eigenständig, steuern sich bei der Erstellung ihrer Leistung selbst und lösen komplizierte Aufgaben durch kooperative Informationsverarbeitung. Jedes Modul erfüllt hierbei einen Zweck, der sich aus den Anforderungen ihres Umfeldes, wenn wir so wollen, aus den Bedürfnissen ihrer Kunden, ergibt. Dieser Zweck gibt den Selektionen des Systems ihre Bedeutung.
Wir erkennen sofort die Ähnlichkeit der Struktur. Während Data as a Product sich aber auf Datenprodukte beschränkt, arbeiten die Geschäftsprozesse mit Kommunikationen, die unterschiedliche Gestalten annehmen können. Es gibt Wertschöpfungsprozesse, die aus der Verarbeitung von Informationen bestehen und Daten herstellen. Es gibt aber auch Wertschöpfungsprozesse, die Waren und Dienstleistungen herstellen.
In allen diesen Fällen können wir Aktionen der Prozesse mit Daten beschreiben, indem wir zählen, messen und wiegen, und Bestände oder Veränderungen in den Blick nehmen. Wir erstellen damit eine Kommunikation über die Kommunikationen des betrachteten Systems. Das IT-Konzept des Data as a Produkt wird zum Repräsentanten einer sehr ähnlichen Struktur. Dazu müssen wir Wertschöpfung als Netzwerk kooperierender Agenten verstehen.
Genau auf diesem Weg finden wir diejenigen Datenprodukte, die wir in einem Data Mesh definieren wollen. Sie repräsentieren dann den Geschäftsablauf und können Impulse für Handlungen auslösen. Und diese Herangehensweise funktioniert gut. Wir haben das in einigen Projekten schon mit Erfolg angewendet.
Beispiel: Zinskurve
In einem großen Treasury-Projekt z.B. haben wir das Objekt der Zinskurve als Data as a Product eingeführt. Normalerweise erwartet man unter dem Begriff “Zinskurve” eine Datenstruktur mit Zeitangaben, Stützpfeilern der Zinskurve und den dazugehörigen Zinssätzen.
In unserer Definition als Produkt haben wir dieses Objekt jedoch zusätzlich mit verschiedenen Methoden ausgestattet. Diese Methoden können beispielsweise mithilfe von Interpolationsverfahren Zinssätze zwischen den Stützpfeilern liefern und die Interpolationsmethode anpassen. Hinter dem Objekt verbirgt sich außerdem eine ganze Welt von Update-, Wartungs-, Pflege- und Entwicklungs-Services. Diese sind zwar für den Nutzer der Zinskurve nicht unbedingt interessant, tragen aber maßgeblich zur Qualität des gesamten Systems bei und ermöglichen klare Verantwortlichkeiten.
Das fachliche Design und die Dokumentation von Systemanforderungen werden dadurch erheblich vereinfacht. Die Zinskurve ist an ihrer Oberfläche lediglich ein Datenobjekt, das beispielsweise in Berechnungen Werte liefert, ohne dass wir uns um die Details kümmern müssen. Dennoch stehen uns alle Möglichkeiten offen, die Vorgänge unter der Oberfläche beliebig komplex zu gestalten.
Diese Auffassung der Leistungserstellung in einem Netzwerk von Zulieferungen korrespondiert stark mit der Vorstellung der objektorientierten Programmierung. In dieser Vorstellung wird eine Programmausführung ebenfalls als ein System kooperativer Objekte betrachtet. Der Unterschied in der Modellierung von Wertschöpfungsprozessen besteht darin, dass die Module in der Lage sind, sich selbständig an die Anforderungen ihrer Umgebung anzupassen. Dabei ist es unerheblich, ob es sich bei dem Modul um ein System handelt, dem wir sein Handeln direkt über menschlichen Einfluss zuschreiben, oder ob es ein Artefakt ist, das sich seine Sprecher sucht und auf diese Weise handelt.
Eine Zinskurve z.B. handelt nicht von sich aus. In unserem Treasury-Projekt hatte die Zinskurve eine ganze Reihe von Experten als Sprecher gefunden. Diese kümmerten sich mit viel Aufwand um die Optimierung ihrer Methoden.
Fazit
Das Konzept des Data as a Product in der IT wird wirksam, wenn es in der Lage ist, Abläufe in den Wertschöpfungstätigkeiten eines Unternehmens sinnvoll zu repräsentieren. Nur dann können aus den Modellen der IT Impulse für Handlungen abgeleitet werden, die die Erwartungen an die Repräsentationsfähigkeit der Datenobjekte erfüllen.
Der vielversprechende Ansatz von Data Mesh und Data as a Product ist also erst dann vollständig, wenn er mit einer kompatiblen Modellierung von Geschäftsprozessen verbunden wird. Beim Design von Software-Systemen ist dieser Schritt dabei der erste.
Die Modellierung von Geschäftsprozessen passt aus meiner Sicht sehr gut zu den Vorstellungen von Data Mesh und Data as a Product. Wir müssen sie hierzu als Modularisierung und Systembildung verstehen. Wenn die Repräsentation zu dem passt, was sie repräsentiert, und gleichzeitig auf die Unabhängigkeit der Module und ihrer Repräsentation als Datenprodukte achtet, dann erreichen wir sicherlich die Flexibilität, die wir zum Handeln unter Unsicherheit brauchen. Das gilt vor allem auch für Anwendungen im Controlling und bei der Steuerung von Unternehmen.
Lassen Sie uns daran arbeiten, und: Make your computers fly!